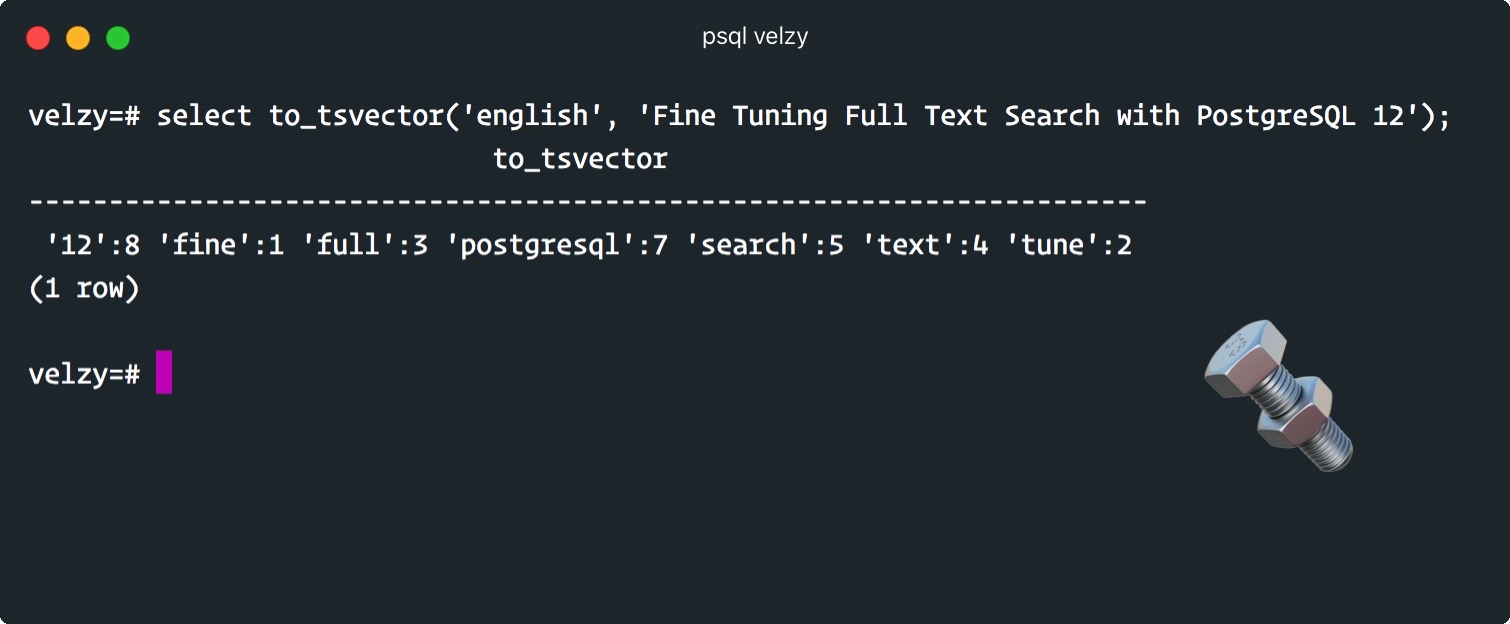
I've written about Full Text Indexing in PostgreSQL before but I was a bit more focused on speed and general use. Today I want to focus on something a lot more useful: relevance.
If you want to play along and have some fun, the SQL for what I'm about to do can be downloaded from here (11K zipped SQL file).
Make Those Results Meaningful!
The data I'm working with is from NDC Sydney and is a list of speakers, their talks, keywords and the time/day of the talk. Simple stuff, but it does present an interesting question:
How would you implement a full text index for this body of data?
Turning the speaker's name, the title and the keywords into a blob of text and then indexing it will work, but it's simply not enough if we expect the results to actually mean something to our users. This is where things get complicated - which also means they get FUN so strap yourself in, let's get TEXTUAL.
What Are You Looking For Anyway?
There's no way we can do this without fully understanding what our users want out of our search functionality, so let's come up with some scenarios:
- Jane has been to 5 conferences already this year and just wants to know what's new with DevOps and Azure. She takes out her phone and, while walking, enters the words as they come to her mind: "devops azure"
- This is Kunjan's first conference and he doesn't know where to start - all he knows is that Heather Downing is speaking and he really wants to be sure he can see her talks so he searches exactly on that: "Heather Downing".
- Nenne is excited about Blazor and knows the dev team is here, showing it off. She can't remember their names - just the project name - so she searches on that: "blazor".
The Problems
We have three difference kinds of searches here:
- The first is contextual, which means that Jane knows the topics she's interested in and wants to throw a list of words at our search, hoping for a ranked match.
- The second is specific, Kunjan wants to see a specific speaker's talk - that means we need to be sure that we can return a hit on exact part of a first or last name.
- Finally, Nenne's query is relative, which means she knows a term (the project name) and wants to see results relative to it.
If we're to show these people something meaningful we'll need to come up with a strategy for building our full text index. Thankfully, Postgres has the tools we need.
Let's take a quick second to (quickly) understand what goes on behind the scenes as our full text index is being created - it's really helpful when trying to debug things. Then we'll move on and create solutions for each of these problems.
Behind the Scenes
A full text index is actually a data type in Postgres called tsvector. It's a weird name, but what it does is pretty simple:
select to_tsvector('english', 'nothing too tricky here');
to_tsvector
---------------------
'noth':1 'tricki':3
(1 row)
I'm using Postgres's built-in to_tsvector function to tokenize my string of words into lexemes. What's a "lexeme" you ask? Hey, good question!
A lexeme is a unit of lexical meaning that underlies a set of words that are related through inflection. It is a basic abstract unit of meaning, a unit of morphological analysis in linguistics that roughly corresponds to a set of forms taken by a single root word.
Wikipedia
You can apply various stems to a lexeme to create a set of different words. So noth in this case could be stemmed to "nothing" or "nothingness". The integers that you see in the results above are the position within the text body. The first word is "nothing" so we have a 1 and tricky is the third word. This comes in handy later on when we want to know positional information (which we will!).
Finally, you'll notice that too and here have been stripped. These are "stop words" (or noise words) and aren't indexed.
But how does all of this tokenization happen?
Postgres ships with a number of dictionaries that parse a given blob of text. If you want to raise the hood on this, you can run the ts_parse function to see what happens:
select * from ts_parse('default', 'nothing too tricky here');
tokid | token
-------+---------
1 | nothing
12 |
1 | too
12 |
1 | tricky
12 |
1 | here
(7 rows)
The first argument to this function is the search configuration, which I'm setting to default as I don't want to break anything. What I get back is a list of tokens and their id. 1, for instance, is an ascii word and 12 is blank space.
You can see a lot more information if you use the ts_debug function, which is designed to help you if you're fiddling with the search config stuff:
select * from ts_debug('nothing too tricky here');
alias | description | token | dictionaries | dictionary | lexemes
-----------+-----------------+---------+----------------+--------------+----------
asciiword | Word, all ASCII | nothing | {english_stem} | english_stem | {noth}
blank | Space symbols | | {} | |
asciiword | Word, all ASCII | too | {english_stem} | english_stem | {}
blank | Space symbols | | {} | |
asciiword | Word, all ASCII | tricky | {english_stem} | english_stem | {tricki}
blank | Space symbols | | {} | |
asciiword | Word, all ASCII | here | {english_stem} | english_stem | {}
(7 rows)
I think this is interesting, but it's also academic for our needs. Let's get back on track and setup our search index.
Task 1: No Stems for Names!
Before we index anything, we need to consider what the thing is and also what it is not. A little vague, but let's start with names.
Names are specific. While one could make the argument that some names might be more common in a given language, I think we can agree that's problematic. In that sense, tokenizing a name as if its English words doesn't make sense.
Heather's last name is "Downing", which could refer to what she might do to a glass of cold water after a long run or what she did to enemy planes during the war. Neither of those is the case, yet that's exactly how the tokenizer will treat her name.
That's how full text queries work in Postgres: matching lexemes. The to_tsquery function you see here simply tokenized the term given to it, applying the rules of the dictionary you specify, which is english in my case:
select to_tsquery('english', 'downing');
to_tsquery
------------
'down'
(1 row)
We can fix this problem by using a different dictionary. This makes perfect sense since we're don't consider names part of a language! For this, Postgres gives us the simple dictionary:
select to_tsquery('simple', 'downing');
to_tsquery
------------
'downing'
(1 row)
The simple dictionary doesn't create a lexeme from the token given to it - it just returns the raw word (unless it's a noise word) lower-cased. This will work perfect for indexing our names:
select to_tsvector('simple', body ->> 'name') from ndc limit 5;
to_tsvector
-------------------------
'alex':1 'mackey':2
'adam':1 'furmanek':2
'kristy':1 'sachse':2
'downing':2 'heather':1
'passos':2 'thiago':1
(5 rows)
Perfect. We'll use this when building our overall index in just a minute.
Applying Weights to Keywords
Proper tagging is difficult to do. I'm not going to spend time on how to do that - let's just assume that you and your app have a cool set of tags you're happy with. Now comes the big question: are those tags words?
On one hand, it seems like the answer should be yes. Tags are contextual and tend to be things like "database", "career", "azure" etc. But what about the tags "virtual-machines" or "virtual-network"?
select to_tsvector('virtual-network');
to_tsvector
---------------------------------------------
'network':3 'virtual':2 'virtual-network':1
(1 row)
select to_tsvector('virtual-machines');
to_tsvector
-------------------------------------------
'machin':3 'virtual':2 'virtual-machin':1
(1 row)
Both of these tags will match on the term "virtual", no matter what it's followed by. That means we'll get a hit on "virtual-conference", "virtual-meeting", and "virtually everything" since the word "virtually" will turn into the lexeme "virtual". That might be OK, it really depends on your tagging strategy. For me, I'll be using the simple dictionary once again because tags are specific, simple terms for this conference.
OK - now let's address the weighting. We can apply weights to our tags by using the setweight function in Postgres:
select setweight(to_tsvector('simple', (body ->> 'tags')),'A')
from ndc limit 5;
'cloud':1A 'fun':2A
'microsoft':2A 'net':1A
'agile':1A 'design':2A 'devops':8A 'methodology':9A 'people':3A 'skills':6A 'soft':5A 'soft-skills':4A 'ux':7A
'agile':1A 'ethics':6A 'people':2A 'skills':5A 'soft':4A 'soft-skills':3A
'cloud':2A 'database':3A 'microsoft':4A 'net':1A
(5 rows)
Weighting is simply a matter of applying a letter suffix to the positional integer. As you can see, cloud:1A has replaced cloud:1. That will be used when we run our query later on.
Oh yeah - something neat to note here is that Postgres is smart enough to take a JSONB array value and turn it into a text array for us, on the fly, and then apply indexing :).
Weighting Considerations
At this point we need to figure out relative weighting for the information we'll be searching. If you have only text blob your indexing, then it doesn't make sense to apply weighting - but that's rarely the case in an online app.
The thing you need to consider when weighting is what "hits" are valued more than others? Weighting doesn't affect which records will be recognized, it simply lifts those records to the top depending on how you weighted them (A through G).
I'm going to make the choice that if someone enters a tag, that should be raised to the top. Next would be someone's name (though you could argue it should be the other way around) and finally whatever was found in the title:
Given this, we can build our entire search index with something like:
select
setweight(to_tsvector('english', (body ->> 'tags')), 'A') || ' ' ||
setweight(to_tsvector('simple', (body ->> 'name')), 'B') || ' ' ||
setweight(to_tsvector('english', (body ->> 'title')), 'C')::tsvector
as search_index
from ndc limit 5;
Note: you'll notice that I'm using the || operator to concatenate the values together, including a space between them. If you don't do this you'll get words jammed together and crappy results.
We've applied the top weight, A, totags and B to name with title coming in last with C. This is just relative ranking, which means that terms found in the keywords are ranked higher than the title, for instance. That will help Jane find her DevOps at Azure talks.
Kunjan will find Heather's talk as we're not stemming - so he won't get confused with bad results. And finally Nenne will easily find her "Blazor" talk as the name appears in the title.
The only tricky part to this is if a speaker's name appears in the title of a talk - so "Juana Blazor" might throw off the result - but there's simply no way we can know which our user might want. We can, however, make the decision that hits in the names should be counted higher! Which is what we did.
Let's add a generated column to our ndc table and test it out!
alter table ndc
add search tsvector
generated always as (
(
setweight(to_tsvector('english', (body ->> 'tags')), 'A') || ' ' ||
setweight(to_tsvector('simple', (body ->> 'name')), 'B') || ' ' ||
setweight(to_tsvector('english', (body ->> 'title')), 'C'))::tsvector
) stored;
This is a new feature in Postgres 12 - generated columns. They're virtual columns that are (for now) stored on disk and completely managed by Postgres. Whenever our record is updated our search index will be too!
We're now ready to start querying.
Constructing a Proper Query
Let's start with the 3rd example first: "blazor", which in Nenne's query. This isn't a keyword match because it's not part of our tags, but it is a project title which will, hopefully, appear in a title somewhere. In that case, we can run the following query just fine:
select
body ->> 'title' as title,
body ->> 'name' as name
from ndc
where search @@
to_tsquery('english', 'blazor');
-[ RECORD 1 ]--------------------------------
title | Blazor, a new framework for browser-based .NET apps
name | Steve Sanderson
-[ RECORD 2 ]--------------------------------
title | Blazor in more depth
name | Steve Sanderson Ryan Nowak
Groovy! We're using our tsvector field, search, and running a comparison with @@ to the to_tsquery function. We get back some results and we can see that we have "Blazor" in the title. Great!
At that point Nenne remembers that Steve Sanderson is one of her favorite speakers, so she decides to search both "blazor" and "Sanderson":
ERROR: syntax error in tsquery: "blazor sanderson"
Oh no! What happened? The short answer is that to_tsquery expects a single word as an argument, which seems really weird at first! I mean... this is a full text search dude! WTF?
The problem is that Postgres doesn't know what you want to do with more than one word. Is it just a collection of words? Or is it a phrase which has some structure to it. The query "blazor Sanderson" doesn't mean anything to you or me, but Jane's query "Azure DevOps" could be considered a phrase, where the term "Azure" needs to come before "DevOps".
For that, we can modify our query using plainto_tsquery:
select
body ->> 'title' as title,
body ->> 'name' as name
from ndc
where search @@
plainto_tsquery('english', 'blazor sanderson');
-[ RECORD 1 ]------------------------------------
title | Blazor, a new framework for browser-based .NET apps
name | Steve Sanderson
-[ RECORD 2 ]------------------------------------
title | Blazor in more depth
name | Steve Sanderson Ryan Nowak
Yes! boom! That works really well. The function plainto_tsquery takes a plain text blob and treats it just like a bunch of words. In fact you can see exactly what it does by asking Postgres:
select plainto_tsquery('blazor sanderson');
plainto_tsquery
------------------------
'blazor' & 'sanderson'
(1 row)
The text gets parsed into individual words, tokenized and turned into lexemes and then placed into a logical AND condition. In other words: both "blazor" and "sanderson" must be in the search index.
But what about Jane's query? She wants to know what's knew with Azure DevOps:
select
body ->> 'title' as title,
body ->> 'name' as name
from ndc
where search @@
plainto_tsquery('english', 'azure devops');
-[ RECORD 1 ]-----------------------
title | Static Sites, Dynamic microservices, & Azure: How we built Microsoft Docs and Learn
name | Dan Fernandez
-[ RECORD 2 ]-----------------------
title | DataDevOps for the Modern Data Warehouse on Microsoft Azure
name | Lace Lofranco
Hmmm. Well that sort of worked in that we have two talks about Azure that also have the term "devops" in the title... however there's nothing there about the Azure DevOps product. One way that we can fix this is to send in a phrase rather than a blob of words using phraseto_tsquery:
select
body ->> 'title' as title,
body ->> 'name' as name
from ndc
where search @@ phraseto_tsquery('english', 'azure devops');
(0 rows)
This is a bit more accurate: there aren't any talks specifically about Azure DevOps. The phraseto_tsquery function leverages the positional argument that's stored with tsvector, making sure that one word will appear before another. You can see this if you ask Postgres what's going on:
select phraseto_tsquery('azure devops');
phraseto_tsquery
--------------------
'azur' <-> 'devop'
The words are tokenized into lexemes once again, but this time there's the positional <-> operator, indicating that "azure" must appear before "devops" in the string (the inclusive AND is implied).
OK, let's make sure that Kunjan can find Heather's talk and then we'll be done! I'll use the regular plainto_tsquery here since I want to be sure we match properly on name:
select
body ->> 'title' as title,
body ->> 'name' as name
from ndc
where search @@
plainto_tsquery('Downing');
(0 rows)
Good grief - no results!?!?! What the heck?
Using the Right Dictionary
The problem we're having is matching dictionaries. When we use to_tsquery or, in this case, plainto_tsquery, the words we pass in will be tokenized according to some kind of dictionary. The default has to do with the location of the server and the default configuration - but it's typically set to the language of the region of the server.
In the case of our name tokens, however, we used the simple dictionary which means that lexemes didn't get generated and therefore will cause a match problem.
To see what I mean, take a look at our plainto_tsquery for "Downing" using the default dictionary (which is "english" in my case):
select plainto_tsquery('Downing');
plainto_tsquery
-----------------
'down'
(1 row)
We're trying to match a literal term to a lexeme, so of course we're going to have problems. We can get over this by using the simple dictionary with plainto_tsquery:
select
body ->> 'title' as title,
body ->> 'name' as name from ndc where search @@
plainto_tsquery('simple','Downing');
-[ RECORD 1 ]------------------------------
title | Keynote: The Care and Feeding of Software Engineers
name | Heather Downing
Much better! But this raises another question...
How Do You Query With Two Dictionaries?
I want to be able to query with both the English and simple dictionaries - but how can I do that and still get reasonable results?
The simplest way to do this with an OR query:
select
body ->> 'name' as name,
body ->> 'title' as title,
body ->> 'tags' as tags
from ndc where
search @@ plainto_tsquery('english', 'heather keynote') OR
search @@ plainto_tsquery('simple', 'heather keynote');
-[ RECORD 1 ]-------------------------------
name | Heather Downing
title | Keynote: The Care and Feeding of Software Engineers
tags | ["agile", "people", "soft-skills", "ethics"]
It's a bit on the verbose side, but as you can see we were able to find Heather's keynote just fine. Note also that I'm using plainto_tsquery here because I'm expecting a word salad, I can change that, however, in the case of names.
We're almost done! Now let's sort our results in a meaningful way.
Ranking The Result Using Our Weighting
Weighting doesn't do much good unless we can apply it, so for that we'll need to make sure there's some form of "score" we can use when querying. For that, we have Yet Another Postgres Function: ts_rank.
There are actually two of these functions. The first is ts_rank which is a score based on word frequency and the second is ts_rank_cd, which is based on frequency but also coverage distance - which is basically how far words are apart in a query. For us, ts_rank will do fine.
To use these functions you have to pass in the tsvector value as well as the tsquery:
select
ts_rank(search,plainto_tsquery('english', 'devops')) +
ts_rank(search,plainto_tsquery('simple', 'devops')) as rank,
body ->> 'name' as name,
body ->> 'title' as title,
body ->> 'tags' as tags
from ndc
where
search @@ plainto_tsquery('english', 'devops') OR
search @@ plainto_tsquery('simple', 'devops')
order by rank desc
limit 5;
-[ RECORD 1 ]-------------------------------------------------------------------------------------
rank | 0.9074664
name | Ashley Noble
title | Trials and Tribulations of a DevOps transformation in a large Company
tags | ["devops"]
-[ RECORD 2 ]-------------------------------------------------------------------------------------
rank | 0.6383234
name | Damian Brady
title | Pragmatic DevOps - How and Why
tags | ["devops"]
-[ RECORD 3 ]-------------------------------------------------------------------------------------
rank | 0.6079271
name | Enrico Campidoglio
title | Understanding Git — Behind the Command Line
tags | ["t", "devops"]
-[ RECORD 4 ]-------------------------------------------------------------------------------------
rank | 0.6079271
name | Pooja BhaumikNick Randolph
title | Using Flutter to develop cloud enabled mobile applications
tags | ["cross-pl", "mobile", "devops"]
-[ RECORD 5 ]-------------------------------------------------------------------------------------
rank | 0.6079271
name | Klee Thomas
title | Picking up the pieces - A look at how to run post incident reviews
tags | ["agile", "devops"]
Update: the original post had the `query bits aliased but, as mentioned by Oleg in the comments, this isn't a very efficient query as it would require nested loops and joins. The query you see here is a bit more verbose, but a lot more efficient.
A few things to note about this code:
- I'm adding the
ts_rankresults together because eachtsqueryis going to have its own score. I'll get into this in a bit. - I limited the results, because there are a lot.
The OR query works great and we're able to query by names, tags and titles and we're almost done - but as you can see the scoring is ... weird.
Postgres does some voodoo math behind the scenes and honestly it doesn't really matter what those scores are all about - what does matter is that some are scored higher than others and we need to make sure our scoring scheme works as we want.
Looking at the top 2 it's easy to see it does: they have the term "devops" as tags as well as the title. This is a classic SEO rule for the web, and we should feel good about our search strategy, don't you think? I guess it can be abused, however, if we pretend it's 1998 and load our title and speaker's name with keywords:
select
ts_rank(search,plainto_tsquery('english', 'devops')) +
ts_rank(search,plainto_tsquery('simple', 'devops')) as rank,
body ->> 'name' as name,
body ->> 'title' as title,
body ->> 'tags' as tags
from ndc
where
search @@ plainto_tsquery('english', 'devops') OR
search @@ plainto_tsquery('simple', 'devops')
order by rank desc
limit 5;
-[ RECORD 1 ]-------------------------------------------------------------------------------------
rank | 0.9074664
name | Ashley DevOps Noble
title | DevOps Trials and DevOps Tribulations of a DevOps transformation in a large DevOps Company
tags | ["devops"]
-[ RECORD 2 ]-------------------------------------------------------------------------------------
rank | 0.6383234
name | Damian Brady
title | Pragmatic DevOps - How and Why
tags | ["devops"]
-[ RECORD 3 ]-------------------------------------------------------------------------------------
rank | 0.6079271
name | Enrico Campidoglio
title | Understanding Git — Behind the Command Line
tags | ["t", "devops"]
-[ RECORD 4 ]-------------------------------------------------------------------------------------
rank | 0.6079271
name | Pooja BhaumikNick Randolph
title | Using Flutter to develop cloud enabled mobile applications
tags | ["cross-pl", "mobile", "devops"]
-[ RECORD 5 ]-------------------------------------------------------------------------------------
rank | 0.6079271
name | Klee Thomas
title | Picking up the pieces - A look at how to run post incident reviews
tags | ["agile", "devops"]
OK it's not perfect, but it's much better than indexing a blob of text because:
- We can recognize speaker names
- We're weighting tag recognition over title
- We're weighting tags and names over the loose text of a title
I think for most web applications this will work really well!
Flexing Postgres 12
Trying to decide between to_tsquery, plainto_tsquery and phraseto_tsquery can be difficult. It was kind of straightforward in our case - we're not searching on any phrases really.
The Postgres team decided to be helpful in this regard, especially when it comes to web applications, so they created websearch_to_tsquery. It basically treats the input as if it were entered into a Google search. To be dead honest I have no idea what's happening under the covers here, but it's supposed to be a bit more intelligent than plainto_tsquery and a little less strict than phraseto_tsquery.
I've played with it a few times and haven't noticed much of a difference - it is worth noting however!
Phew! Long post - hope it was helpful!