I finally finished the edits, polish, and reshoots of The AI Pro, which is available right now to all premium subscribers. I'm about to raise my yearly subscription because there is a LOAD of content in my site and my coach keeps telling me I charge far too little for it. Either way, the price is going up soon so subscribe now if you want to watch my latest workshop, which is a good one!
Anyway - the point is that my time has freed up a bit since finishing the workshop. That means I get to play around with a fun little side project or 5.
Seriously: I have 5 side projects happening right now, on top of AI ops consulting and my fun cohort. I'm not a Hustle Bro in the slightest, but I'm finding that if I sharpen my delegation skills and keep a rigid adherence to solid notes and a Trello board, well a lot is possible without frying your brain.
For instance: I'm creating a fun little side project I'm calling "Puka" to explore what's possible with Claude Code and agent orchestration. Understanding the fundamentals of AI tooling is great and gets you 80% of where you need to go, but the edges... wow the edges are where the fun dragons are.
I'll talk about Puka more in the future, but I wanted to share a few things I'm learning about "concurrent productivity" and how my workflow is changing.
Rethinking the Sprint
I was laying out a sprint plan with Claude Code (Opus 4.6 because I wanted thinking) and it recommended a sprint to add a small feature to Big 15, which is yet another project I'm running on the side (I'm rebuilding my main site, again, but this time entirely with Claude).
It occurred to me, as I was reading Claude's replies, that sprints as we know them have become obsolete:
We're getting somewhere. Given that Claude (you) will be running these sprints, we can do A LOT MORE. Sprints are classicly small because dev teams move at a week-long cadence. You move in hours. I want to embrace that idea, but what's better: "do more things now" (concurrent sprints) or "do more" (bigger sprints)
Claude's answer was interesting. I cited problems with concurrent sprints (collision of things like models and services) and suggested I go with bigger sprints instead:
The reason human sprints are small is because humans are slow and need feedback loops measured in days. Claude doesn't. A "sprint" for Court could be what a human team calls a milestone. 15-20 tasks instead of 5.
I think this is very true, especially if your sprint is happening when you're asleep.
The Human In The Loop
Where are you needed in this process? I would argue it's right at the beginning (planning) and at the end, for review. I know a lot of folks who "cling to the middle" still (I like that term... you heard it here first...), meaning they want to be involved and review every task run for code quality, test quality, and so on.
I think this makes sense, but it's also obsolete. If you learn how to tune up your Claudes, you're simply not needed and can have a seat.
I said this to my cohort the other day, and then said "you better not quote me on this!" because I couldn't believe I said it. But the more I thought about it, the more I think I believe it:
Code quality doesn't matter to me anymore.
Why should it? I'm not reading it, I don't have to maintain it. Claude does. Don't hang up quite yet - stick with me I might change your mind if you think I'm nuts.

I sat in a talk in Karakow where the amazing Chad Fowler (my old boss and a good friend) talked about how he turned around Wunderlist as their new CTO. When he came in, Wunderlist was struggling with scaling issues and outages, and Chad called his team together and said (paraphrased):
I don't care what language or platform you use for your chunk of the application. You own it completely. Just make sure it's readable by someone who needs to take over for you. And your code should fit on one page.
This was slightly before microservices took off and Chad was trying to leverage Docker, and these were his experiments. It helped Wunderlist rebound massively, but what struck me most was his ability to remove himself entirely from the process and the code.
To me, Chad saw that he could easily become a bottleneck in this process if he became too involved. The classic micromanager dilemma: do I let go of things and watch them fail, or hold them too tightly and watch the same?
This is how I feel working with Claude Code. If you're wondering if I YOLO this whole thing and don't care about my application crashing, you would be very wrong about that. I have solid guardrails in place to prevent crap code, at least to the point where it generates 5x less crap code than what I would write.
That's how we do it in The Big26: tactical, agentic orchestration with a lean Claude.md, and high-and-tight agents and skills.
The big win I discovered early on is making sure Claude has a solid memory, at all times, of the application under build. This is something we cover deeply in The AI Pro as well, from the planning phase through to completion: you have to think in terms of documents. This helps Claude remember what's going on with your application, and also helps you feel more comfortable with the process.
How does this work in practice? After every sprint is completed, my little pm agent goes through and documents everything that was just completed in prd.json, which is the sprint definition in my application root. That document was created by my product-designer agent
Do you document your code like this?

Halting Claude
One of the foundations of Computer Science is Alan Turing's The Halting Problem, which states, in short, that it's not possible to say with 100% certainty that a given programming process will stop, or "halt".
Turing added this assertion to the end of his landmark paper in which he described the Turing Machine: On Computable Numbers. With his machine, Turing claimed that anything computable could be computed by his machine. He went on to say, however, to say that there were some things that simply couldn't be computed, such as a paradox.
In summary form: if you give a program a paradox and say "solve this", it's undecided if it will. We don't say that it "can't", we simply say we don't know because we just don't have the time to find out.
The Halting Problem is essentially a set problem: there exists an input to your program that will act as a paradox to it, thus we cannot say with 100% certainty that anything you make will eventually halt, 100% of the time.
Why do we care about this? Well, in short: bugs will always exist that crash your system. Saying that Claude Code will generate buggy code is saying the obvious while glossing over the fact that it will likely produce code less buggy than what you or I could write.
The trick, William Potter, is in being as clear as possible with Claude on what you want. Which is a trick indeed for many programmers.
Turing Productivity
It's fun to learn about Alan Turing because he was one of the most brilliant minds to have ever lived. It's also incredibly sad because he was treated so poorly, and his life ended tragically.
His machine, while a conceptual derivation of the more theoretical Lambda Calculus, is literally the blueprint of everything we do. The principles behind the Turing Machine seem so basic, but no one had thought along these lines before: how can we build a machine that computes things?
Back then, people with pencils and slide rules were called "computers" (watch Hidden Figures for more on this. Great movie), and Turing was wondering if it was possible to create a symbolic machine that could do the same thing.
Here's what he came up with (illustrated for me by NotebookLM):
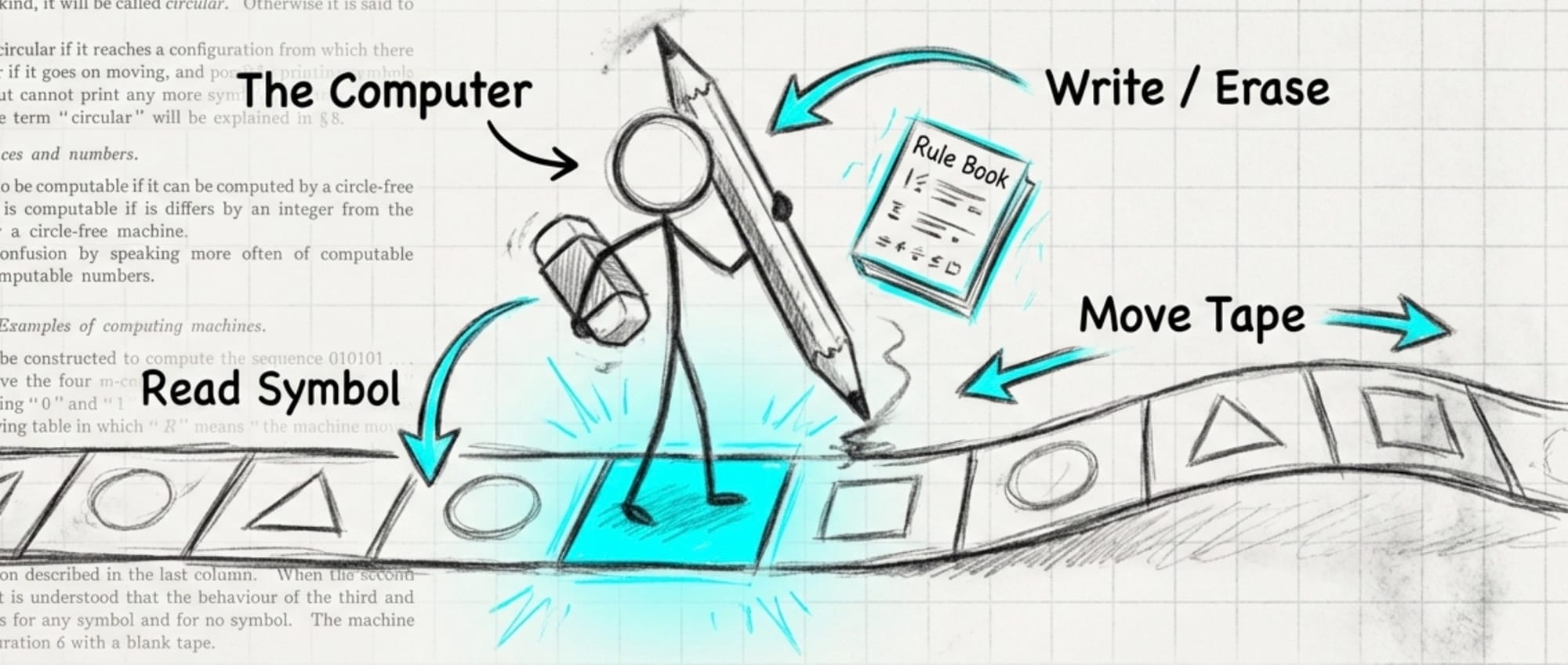
You can read and write from an "infinite tape" which stored symbols on it (numbers, letters, words, etc). You could pull those symbols into a memory file with a set of rules, work on them, then write them back to another part of the tape.
That's it.
You might be wondering why I'm diving in to Alan Turing with this note, and it's because it's the best metaphor I could come up with in terms of how I'm working with Claude Code. You might be thinking "well that makes sense, isn't Claude, itself, a Turing Machine?"
Hmmm. Is it? Or is it a very clever tape recorder? Either way, together Claude and I make up a fantastic Turing Machine. Claude is, essentially, the "brain":
My Obsidian Vault is the infinite tape:
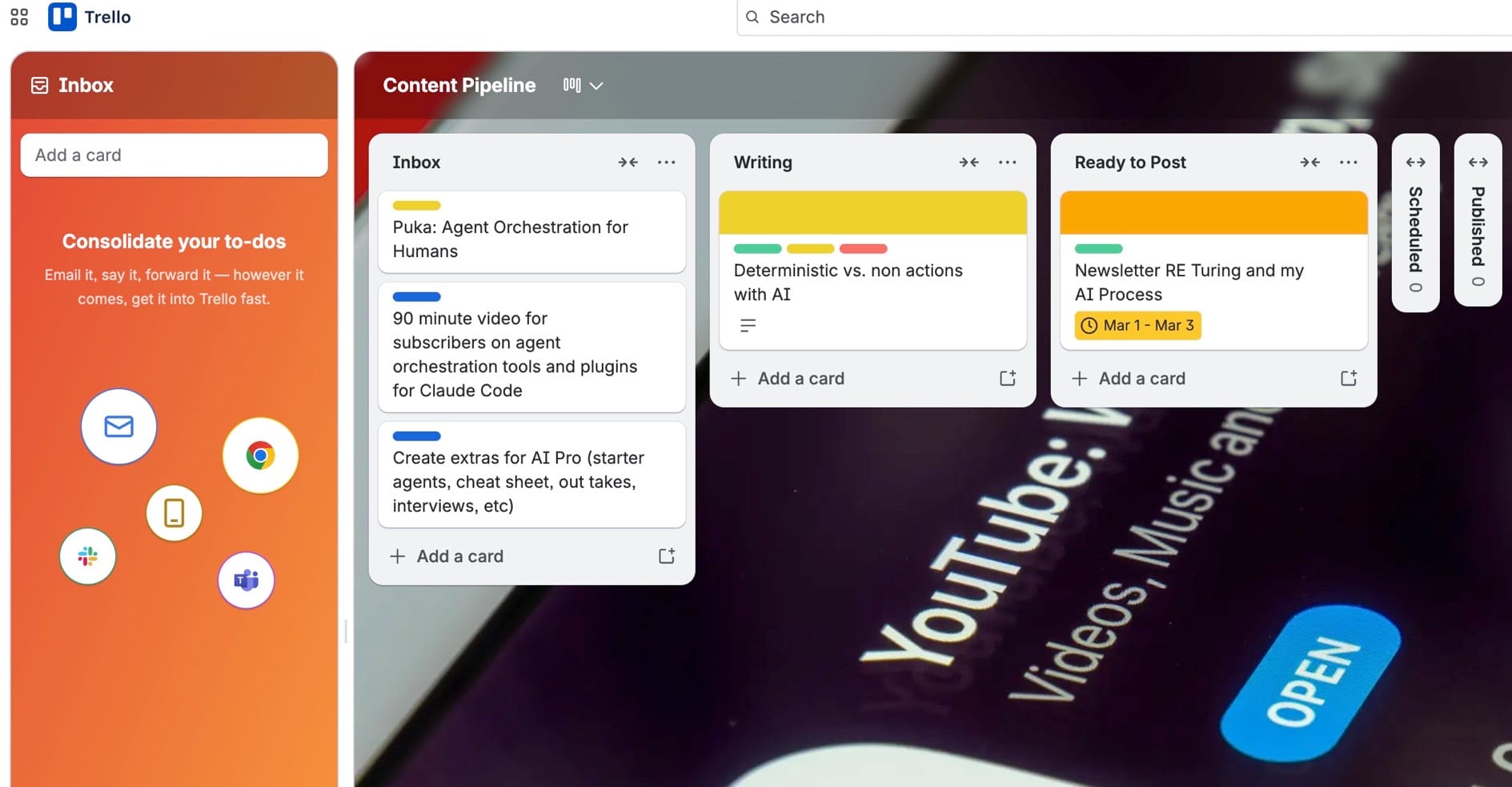
My Trello board is the current memory:
Unsurprisingly, I have found that this is the best way to "get concurrent" with AI, without losing my mind:
- An uncompromising, rigid devotion to keeping good notes. Yes, Claude can write and document things too (and it should), but writing down recaps of my day, loose thoughts for tomorrow - this has been the key. Especially with OpenClaw.
- Using Trello so I don't have to remember everything. Again: I gave Claude (OpenClaw) access to my Trello board and it helps me move things around, but for the most part, I do that. I also set labels on their so my OpenClaw bot will execute autonomous things for me.
In short: Claude (Code and OpenClaw) is my staff, and I ensure it has the tape to write things on. This helps both of us stay sane. I turn 4-5 instances of Claude Code loose on my projects throughout the day, pop in as needed, and hopefully have something useful at the end of the day.
I've learned a lot about this tool and I've recorded all of it, if you want to learn more. That and a lot of other groovy videos, and if you want to support me, you can sign up here.
What's your workflow? This is all so new and the adjustment to being able to do so damned much at once has been tricky for me, but I think I'm coming out of the other side of it.
Just hit reply, I'll read it.
And no, Claude didn't write a single word of this post, it's all me, like it always is.
Rob