
Just yesterday I was talking to a friend about Postgres (not uncommon) and he said something that I found shocking:
I can't even with Postgres, I know JACK SQUAT
This person calls themself my friend too! I just don’t even know what’s real anymore.
So, Friendo is a Node person who enjoys using a document database. Can’t blame him - it’s easy to setup, easy to run and you don’t need to stress out about SQL and relational theory. That said, there are benefits to wrapping structure and rules around your data - it is the lifeblood of your business after all.
If you’re like Friendo and you want to start from the very beginning with Postgres, read on! I’ll use his questions to me for the rest of this post. He has a lot of questions, so I'm going to break this up into parts:
- Part 1 (this post) is for people who've never thought about a database before, let alone set one up and run a query
- Part 2 (next post) will be for Node people wondering what/why/how they could work with Postgres
I encourage you to play along if you're curious. If you're having fun and want to do more, I wrote a really fun book about Postgres and the data from the Cassini mission (which you'll see below) that you're welcome to check out too!
Where is Postgres? How do I get it and run it?
The easiest possible thing you can do is to run a docker image, which you can do by executing:
docker run -p 5432:5432 postgres:12.1
That will download and run a Postgres image, exposing the default Postgres port of 5432.
If you’re not a Docker person and are on a Mac, you can also head over to postgresapp.com where you can download a free executable app.
How do I manage it with a tool?
Tooling for Postgres is both abundant and wanting. There is no clear cut answer to this question other than to offer the following options for a given context.
Just playing around: Mac If you’re on a Mac go get yourself a free copy of Postico. It’s easy and you can quickly connect and start playing.
Just playing around: Windows (and Mac)
There’s the free Azure Data Studio which uses the same interface as VS Code. There are extensions and all kinds of goodies you can download if you want as well.
To hook up to Postgres, make sure you grab the Postgres extension. You can install it right from the IDE by clicking on the square thingies in the bottom left of the left-most pane.
Something substantial and you’re willing to pay for it (Windows and Mac) My go-to tool for working with Postgres is Navicat. It’s a bit on the spendy side but you can do all kinds of cool things, including reports, charting, import/export, data modeling and more. I love this thing.
Don’t know what to choose? Just download Azure Data Studio and let’s get to work!
Our first login Let’s connect to our new shiny Postgres server. Open up Azure Data Studio and make sure you have the Postgres extension installed. You’ll know if you do because you’ll see the option to connect to PostgreSQL in the connection dialog:
The server name is “localhost” and the Docker image comes with the login preset - “postgres” as the user name and “postgres” as the password.
We’ll go with the default database and, finally, name our connection “Local Docker”. Click “Connect” and you’re good to go.
Our first database Most GUI tools have some way of creating a database right through the UI. Azure Data Studio doesn’t (for Postgres at least) but that’s OK, we’ll create one for ourselves.
If you’ve connected already, you might be wondering “what, exactly, am I connected to”? Good question Friendo! You’re connected to the default database, “postgres”:
This is the admin playground, where you can do DBA stuff and feel rad. We’re going to use our connection to this database to create another one, where we’re going to drop some data. To do that, we need to write a new query. Click that button that says “New Query”:
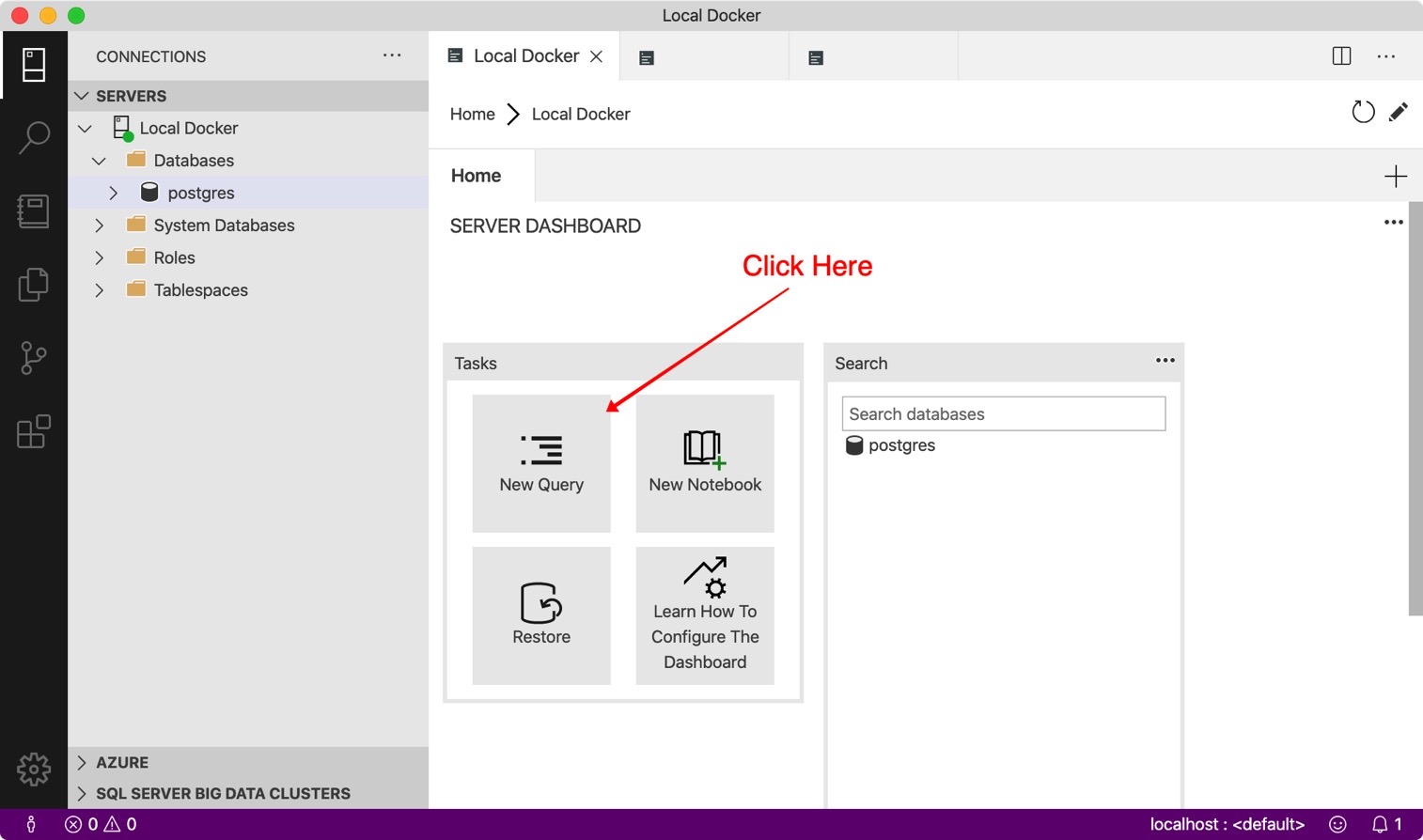
In the new query window add the following:
create database cassini;
Now hit “F5” to run the query. You should see a success message like so:
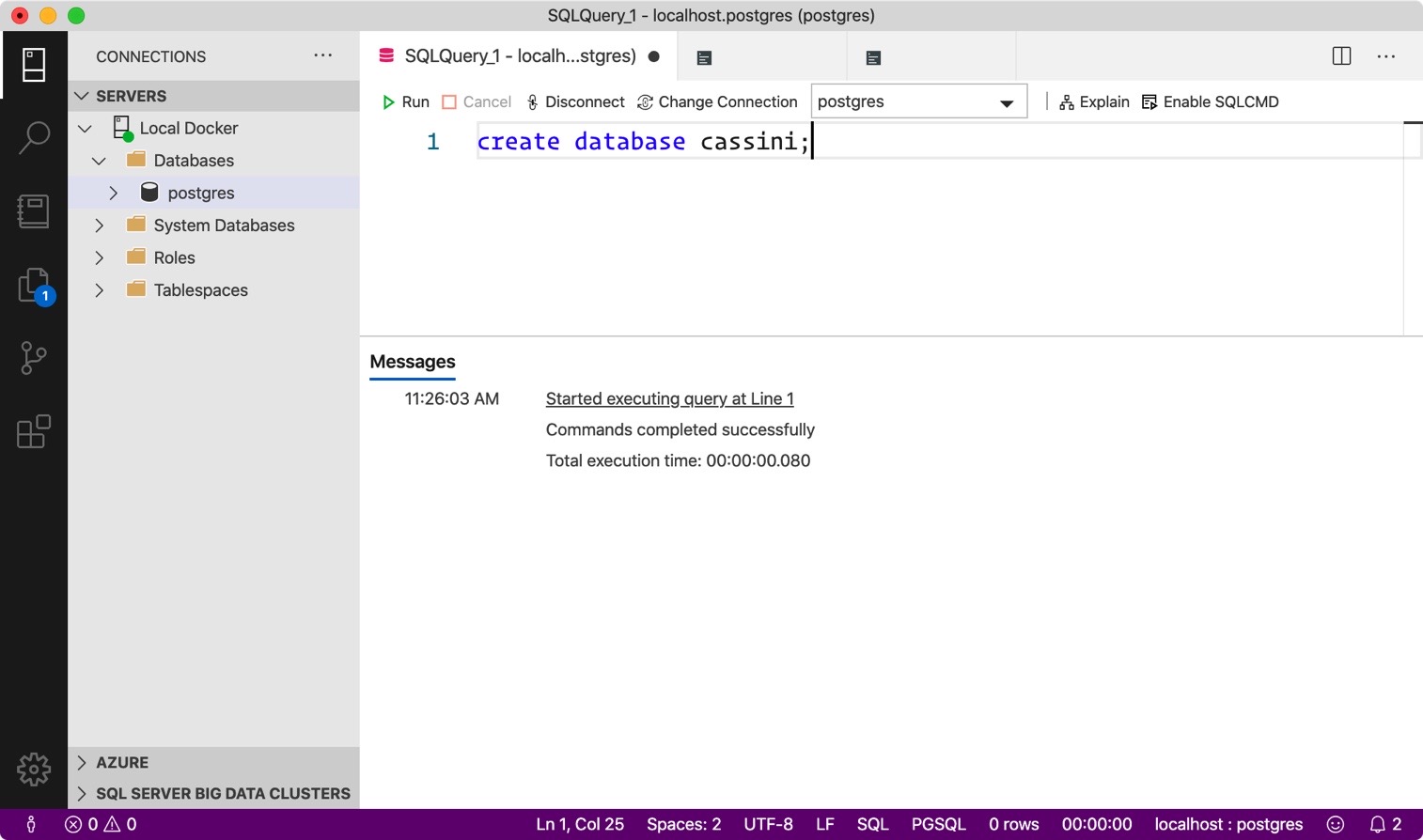
If you see a syntax error, check your SQL code and make sure there are no errors. You’ll also notice that nothing changed in the left information pane - there’s no “cassini” database! What gives!
Ease up Friendo! Just right click on the “Databases” folder and refresh - you should see your new database. Once you see, double-click it and in we go!
Our first table Our database is going to hold some fun information from the Cassini Mission, the probe that we sent to Saturn back in 1997. All of the data generated by the project is public domain, and it’s pretty fun to use that data rather then some silly blog posts don’t ya think?
There’s a whole lot of data you can download, but let’s keep things reasonable and go with the “Master Plan” - the dates, times and descriptions of everything Cassini did during it’s 20 year mission to Saturn. I trimmed it just a bit to bring the file size down, so if you want to play along you can download the CSV from here.
We’ll load this gorgeous data in just one second. We have to create a table for it first! Let’s do that now by opening a new query window in Azure Data Explorer (which I hope you remember how to do). Make sure you’re connected to the “cassini” database, and then enter the following SQL:
create table master_plan(
date text,
team text,
target text,
title text,
description text
);
This command will, as you might be able to guess, create a table called “master_plan”. A few things to note:
- Postgres likes things in lower case and will do it for you unless you force it to do otherwise, which we won’t.
- We don’t have a primary key defined, this is intentional and you’ll see why in a second.
- There are a number of ways to store strings in Postgres, but the simplest is
text, without a length description. This is counterintuitive for people coming from other databases who think this will take up space. It won’t, Postgres is much smarter than that. - Why are we storing a field called “date” as
text? For a very good reason which I’ll go over in just a minute.
OK, run this and we should have a table. Let’s load some data!
How do I load data into it?
We’re going to load data directly from a CSV, which Postgres can do using the COPY command. For this to work properly, however, we need to be sure of a few things:
- We need to have the absolute path to the CSV file.
- The structure of the file needs to match the structure of our table.
- The data types need to match, in terms of format, the data types of our table.
That last bit is the toughest part. CSV (and spreadsheets in general) tend to be a minefield of poorly chewed data-droppings, mostly because spreadsheet programs suck at enforcing data rules.
We have two ways to get around this: suffer the pain and correct the data when we import it or make sure all the import columns in our database table are **text**. The latter is the easiest because correcting the data using database queries tends to be easier than editing a CSV file, so that’s what we’ll do. Also: it’s a good idea not to edit the source of an import.
Right - let’s get to it! If you’re running Docker you’ll need to copy the master_plan CSV file into your running container. I put my file in my home directory on my host. If you’ve done the same, you can use this command to copy the file into your container:
docker cp ~/master_plan.csv [CONTAINER ID]:master_plan.csv
Once it’s there, you can execute the COPY command to push data into the master_plan table:
COPY master_plan
FROM '/master_plan.csv'
WITH DELIMITER ',' HEADER CSV;
This command will grab the CSV file from our container’s root directory (as that’s where we copied it) and pop the data in positionally into our table. We just have to be sure that the columns align, which they do!
The last line specifies our delimiter (which is a comma) and that there are column headers. The final bit tells Postgres this is a CSV file.
Let’s make sure the data is there and looks right. Right-click on the table and select “Select top 1000 rows” and you should see something like this:
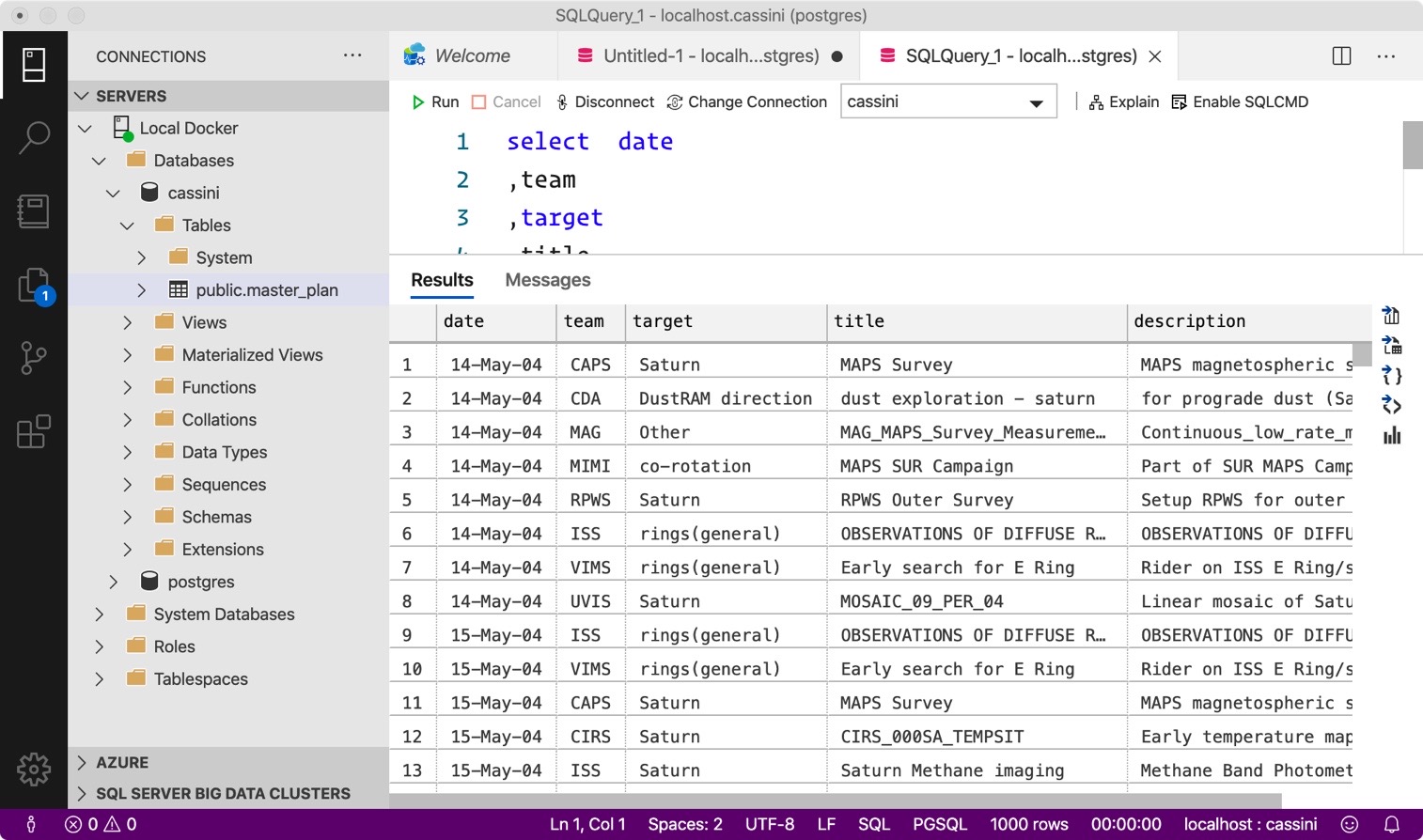
Yay data! Before we do anything else, let’s add a primary key so I don’t freak out:
alter table master_plan
add id serial primary key;
Great! Now we’re ready to connect from Node.
How do I connect to it from Node?
Let’s keep this as simple as possible, for now. Start by creating a directory for the code we’re about to write and then initializing a Node project. Feel free to use Yarn or NPM or whatever!
Open up a terminal and:
mkdir pg_demo
cd pg_demo
npm init -y
npm install pg-promise
touch index.js
These commands should work in Powershell on Windows just fine.
We’ll be using the promise-based Postgres driver from Vitaly Tomalev called pg-promise, one of my favorites. The default Node driver for Postgres works with standard callbacks, and we want promises! There are also a few enhancements that Vitaly thew in which are quite nice, but I’ll leave that for you to explore.
The first step is to require the library and connect:
const pgp = require("pg-promise")({});
const db = pgp("postgres://postgres:postgres@localhost/cassini");
I’m connecting to Postgres using a URL-based connection string that has the format:
postgres://user:password@server/db_name
Since we’re using Docker, our default username and password is “postgres”. You can, of course, change that as needed.
Once we’ve set up the connection, let’s execute a query using some very simple SQL:
const query = async () => {
const res = await db.any("select * from master_plan limit 10");
return res;
};
Because pg-promise is promise-based, I can use the async and await keywords to run a simple query. db.any will return a list of results and all I need to do is to pass in a SQL string, as you see i did. I made sure to limit the results to 10 because I don’t want all 60,000 records bounding back at me.
To execute the query, I call the method and handle the returned promise. I’ll pop the result out to the console:
query()
.then((res) => {
console.log(res);
})
.catch((err) => {
console.error(err);
})
.finally(() => {
db.$pool.end();
});
The last line in the finally block closes off the default connection pool, which isn’t required but the Node process won’t terminate unless you do (you’ll have to ctrl-c to stop it otherwise).
You can run the file using node index.js from the terminal, and you should see something like this:
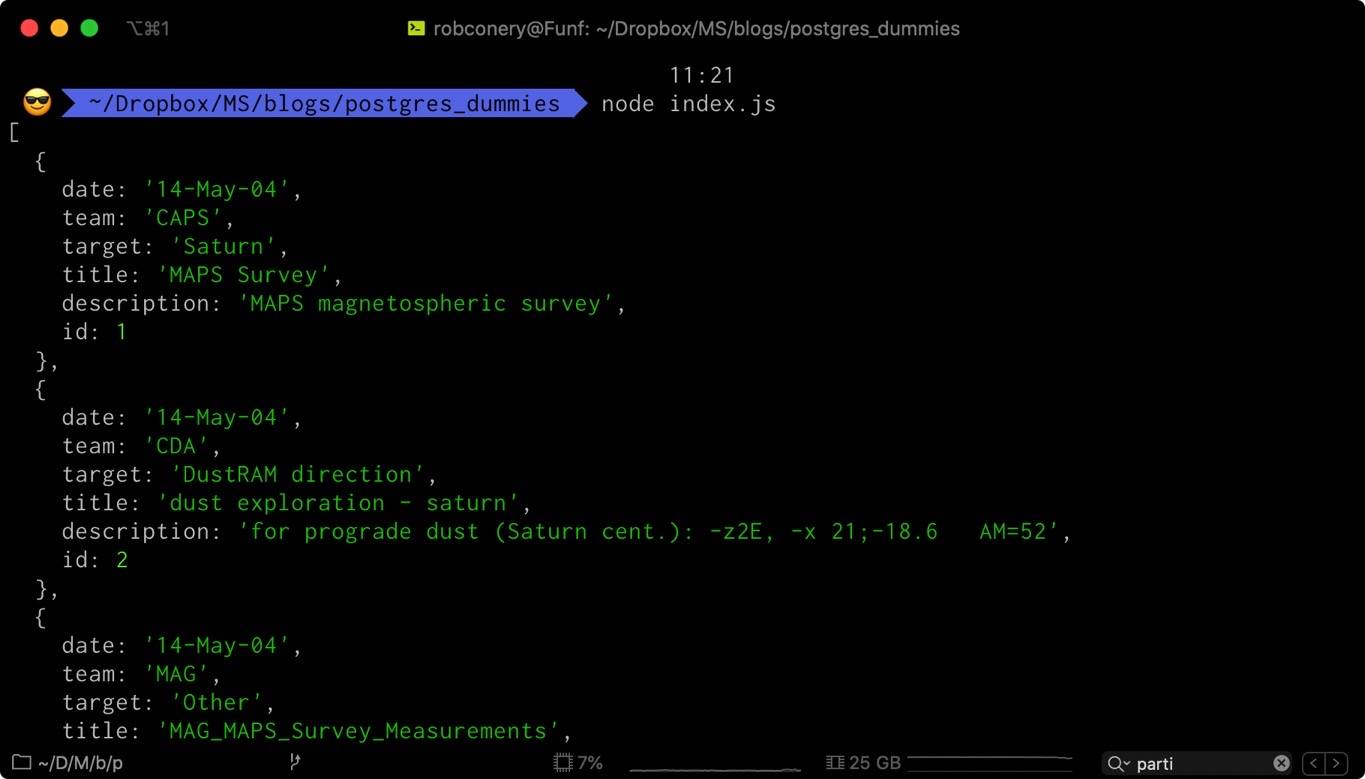
Glorious data! Notice it all comes back in lovely, formatted JSON, just as we like.
There’s a lot more we can do, but this post is already quite long and I think Friendo might have a few more questions for me. I’ll see if he does and I’ll follow up next time!