Isolating the Enceladus Data
2 hours of SQL video using NASA's Cassini data. See why developers become data pros.
We'll start by creating a script to transform the imported data into something we can analyze later on. For that, we'll use bash:
<span class="hljs-built_in">mkdir</span> enceladus <span class="hljs-comment">#if you haven't already</span>
<span class="hljs-built_in">touch</span> enceladus/transform.sql
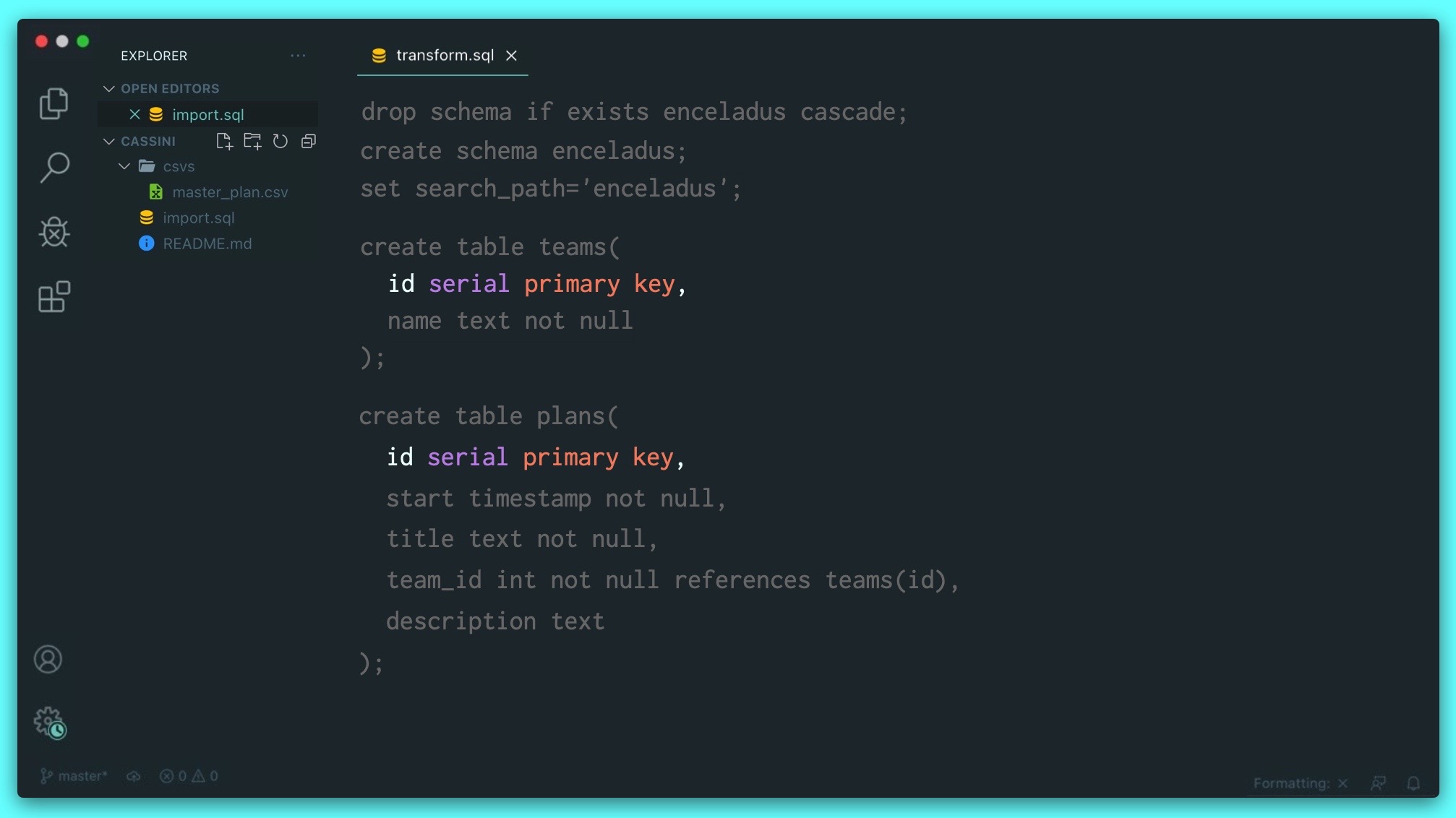
Once again, we'll create a schema to work in, but this time we'll ensure the script is idempotent from the start. As a convenience, we'll tell Postgres that every bit of SQL that's to come is to be run in the enceladus schema. We can do that by setting the search_path:
<span class="hljs-keyword">drop</span> schema if <span class="hljs-keyword">exists</span> enceladus cascade;
<span class="hljs-keyword">create</span> schema enceladus;
<span class="hljs-keyword">set</span> search_path<span class="hljs-operator">=</span><span class="hljs-string">'enceladus'</span>;
Creating our teams and plans table, which are related by a foreign key, which is the team_id in the plans table. It references the id of the teams table. We specify that using the keyword references:
<span class="hljs-keyword">drop</span> schema if <span class="hljs-keyword">exists</span> enceladus cascade;
<span class="hljs-keyword">create</span> schema enceladus;
<span class="hljs-keyword">set</span> search_path<span class="hljs-operator">=</span><span class="hljs-string">'enceladus'</span>;
<span class="hljs-keyword">create table</span> teams(
id serial <span class="hljs-keyword">primary key</span>,
name text <span class="hljs-keyword">not null</span>
);
<span class="hljs-keyword">create table</span> plans(
id serial <span class="hljs-keyword">primary key</span>,
<span class="hljs-keyword">start</span> <span class="hljs-type">timestamp</span> <span class="hljs-keyword">not null</span>,
title text <span class="hljs-keyword">not null</span>,
team_id <span class="hljs-type">int</span> <span class="hljs-keyword">not null</span> <span class="hljs-keyword">references</span> teams(id),
description text
);
Now we need to add some data and we can do that using a new SQL friend, insert. You can insert data in two ways: using the results of a query or by creating a set of hard-coded values. We'll use a query:
<span class="hljs-keyword">insert into</span> teams(name)
<span class="hljs-keyword">select</span> <span class="hljs-keyword">distinct</span> team <span class="hljs-keyword">from</span> csvs.master_plan;
<span class="hljs-keyword">insert into</span> plans(<span class="hljs-keyword">start</span>, title, team_id, description)
<span class="hljs-keyword">select</span>
start_time_utc::<span class="hljs-type">timestamp</span>,
title,
(<span class="hljs-keyword">select</span> id <span class="hljs-keyword">from</span> teams <span class="hljs-keyword">where</span> name<span class="hljs-operator">=</span>csvs.master_plan.team),
description
<span class="hljs-keyword">from</span> csvs.master_plan
<span class="hljs-keyword">where</span> target<span class="hljs-operator">=</span><span class="hljs-string">'Enceladus'</span> <span class="hljs-keyword">and</span> title <span class="hljs-keyword">is</span> <span class="hljs-keyword">not null</span>;
2 hours of SQL video using NASA's Cassini data. See why developers become data pros.